E Esse Tal de Nano Service?
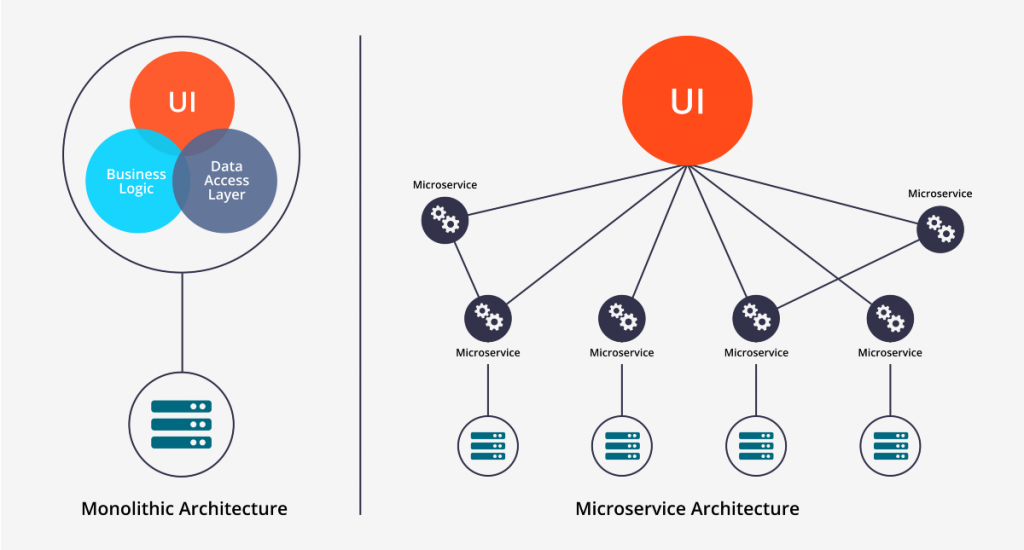
Ao longo dos anos, o desenvolvimento de software se afastou das arquiteturas monolíticas tradicionais, abordando suas complexidades com código fortemente acoplado e interconectado. Isso resultou na adoção de microsserviços, abordagens eficientes nativas da nuvem que permitem a computação distribuída por meio de vários serviços menores. Desde que os microsserviços se tornaram mainstream, nos últimos anos, os nanoservices evoluíram como outro padrão que foi projetado principalmente para superar as complexidades encontradas nos microsserviços. Essencialmente, os nanoserviços dividem ainda mais os serviços para trazer eficiência adicional. Este artigo descreve como o desenvolvimento de componentes menores para criar um aplicativo é uma abordagem preferencial, portanto: Explicar micro e nanoserviços Explore benefícios e desafios Compartilhe exemplos e práticas recomendadas para ajudá-lo a determinar a estrutura certa para suas necessidades Melhorando as práticas de desenvolvimento Dev...
